GFS, HDFS AND THEIR DIFFERENCES.
I. GOOGLE FILE SYSTEM (GFS)
The Google File System (GFS), is a proprietary distributed file system developed by Google Inc., which supports all of its information processing infrastructure in the cloud. It is specially designed to provide efficiency, data access reliability using massive cluster processing systems in parallel.
As a result of providing services from Google, Google faces the requirement to manage large amounts of data that include. Based on a large number of comparatively small servers, GFS is designed as a distributed file system to run in groups of up to thousands of machines. In order to facilitate the development of applications based on the GFS model, the file system provides a programming interface aimed at the abstraction of these aspects of distribution and management.
As it is not a file system for general use, GFS has been designed taking into account the following premises: that a component fails is the norm, not the exception, the files are huge (many GB files are common), it is very common that a file changes because data is added but it is very rare that existing data is overwritten; the coding of the applications and the file system API provides a global benefit.
Architecture

GFS is a distributed system that runs in clusters. The architecture is based on a master / slave model. Whereas the master is primarily responsible for managing and monitoring the cluster, all data is stored on the slave machines, which are known as chunkservers. In order to provide sufficient data security, all data is replicated in a number of chunkservers, the default value starts in three. While the exact replication algorithms are not fully documented, the system also tries to use machines located in different racks or even in different networks for the storage of the same piece of data. In this way, the risk of data loss in the event of a failure of an entire grid or even subnetwork is mitigated.
To carry out such distribution in an efficient manner, GFS employs a number of concepts. First and foremost, the files are divided into chunks, each having a fixed size of 64 MB. A file always consists of at least one piece, although pieces are allowed to contain a payload smaller than 64 MB. New blocks automatically assign in the case of the growth file. Pieces are not only the one unit of management and their role therefore can be roughly compared to blocks in ordinary file systems, they are also the unit of distribution. Although the client code occupies the files, the files are nothing more than an abstraction provided by GFS in which a file refers to a sequence of portions. This abstraction is supported mainly by the teacher, who manages the allocation between the files and the pieces as part of their metadata. Chunkservers in turn occupy exclusively the pieces, which are identified by unique numbers. Based on this separation between files and blocks, GFS gains the flexibility of the file replication application solely on the basis of replicating chunks.
As the master server has the metadata and manages file distribution, it is involved when chunks must be read, modified or deleted. In addition, the metadata managed by the teacher must contain information about each individual fragment. The size of a portion (and therefore the total number of blocks) is therefore a key calculate influence on the amount of data and interactions the teacher has to handle.
Election of 64 MB as serving size can be considered as a trade-off between trying to limit the use of resources and the main interactions, on the one hand and accept a greater degree of internal fragmentation on the other side. In order to protect against disk damage, chunkservers need to verify the integrity of the data before being delivered to a client by using checksums. To limit the amount of data needed to be read again in order to recalculate a checksum if the parts of a piece have been modified during a write operation.
The sums are not created in good part-granularity, but in granularity blocks. Blocks, that do not correspond to present blocks of the system, with 64 KB of size and are a logical subcomponent of a fragment.
GFS is implemented as user-mode components that run on Linux Operating System. As such, it exclusively aims to provide a distributed file system by leaving the task of disk management (that is, the function of a file system in the context of operating systems) for Linux file systems. Based on this separation, chunkservers store each fragment as a file in the Linux file system.
Metadata
The master stores three important types of metadata: the namespace of files and pieces, the correspondence of files in pieces and the location of the replicas of the pieces. All information is stored in memory, which means that operations are fast. In addition, it is easy and efficient for the master to perform periodic checks that are used for garbage collection, re-replication in case of failures in the chunkserver and the migration of pieces for load balancing.
The master does not keep a persistent record that chunkserver has a replica of a particular chunk but requests this information from the chunkserver at the beginning. The master can update his saved information after this since he controls all the chunkserver and monitors the status of these with regular HeardBeat messages.
II. HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
Hadoop File system has been developed using distributed file system design. It runs on commodity hardware. Unlike other distributed systems, HDFS is very tolerant and designed using low cost hardware.
HDFS has a large amount of data and provides easier access. To store this large data, the files are stored on several machines. These files are stored redundantly to rescue the system from possible data loss in case of failure. HDFS also allows parallel processing applications.
Characteristics of HDFS.
- It is suitable for storage and distributed processing.
- Hadoop provides a command interface to interact with HDFS.
- The servers of namenode datanode and help users to easily check the status of the cluster.
- Streaming access to file system data.
- HDFS provides file permissions and authentication.
Architecture
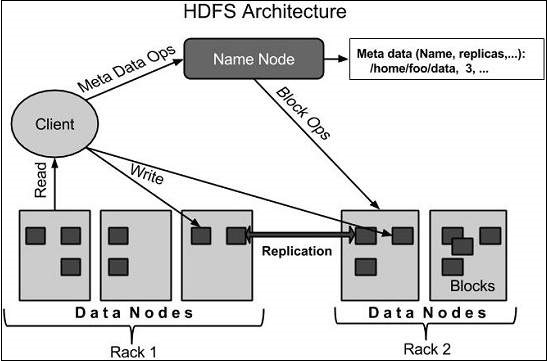
HDFS follows the master-slave and architecture that has the following elements:
The namenode is the basic hardware that contains the GNU / Linux operating system and the namenode software. It is software that can be executed in hardware. The system that has the namenode acts as the master server and not the following tasks:
- Manage the namespace of the file system.
- The client regulates access to files.
- In addition, it executes file system operations such as renaming, closing and opening files and directories.
Datanode is a commodity hardware with the GNU / Linux operating system and datanode software. For each node (Commodity hardware / System) of a cluster, there will be a datanode. These nodes manage the storage of your system's data.
- Datanodes perform read and write operations of file systems, as per client's request.
- In addition, they allow operations such as creation, deletion, with which replication according to the instructions of the namenode.
In general, user data is stored in the HDFS files. The file in a file system is divided into one or more segments and / or stored in the data nodes. These segments are called as blocks. In other words, the minimum amount of data that HDFS can read or write is called a block. The default block size is 64 MB, but it can be increased by the need to change HDFS settings.
III. DIFFERENCES BETWEEN HDFS AND GFS
HDFS contain single NameNode and many DataNodes in is file system. GFS contain single Master Node and multiple Chunk Servers and is accessed by multiple clients.
Default block size in GFS is 64MB and default block size in HDFS is 128MB and both of this file system blocks can be altered by the user.
In GFS master does not keep a persistent record of which chunkservers have a replica of a given chunk. It simply check the status of the chunkservers for that information at startup. In HDFS chunk location information consistently maintained by NameNode.
GFS provides record append with this client specifies the offset at which data is to be written. It allows many clients on different machines append to the same file concurrently with this random file writes are possible. GFS allows multiple writer and multiple reader. In HDFS only append is possible.
In GFS ChunkServers use checksums to detect corruption of the stored data. Comparison of the replicas is another alternative. The HDFS client software implements checksum checking on the contents of HDFS files when DataNode arrives corrupted.
GFS has unique garbage collection process. The resources of deleted files are not reclaimed immediately and are renamed in the hidden namespace which are further deleted if they are found existing for 3 days of regular scan. In HDFS Deleted files are renamed into a particular folder and are then removed via garbage collection process.
Individual files and directories can be snapshotted in GFS. Up to 65,536 snapshots allowed for each directory in HDFS.
PDF File:
GFS, HDFS and their differences - Vega, Ernesto
